Performance Benchmarking#
This page documents code and results of benchmarking various robotics simulators on a number of dimensions. It is still a WIP as we write more fair benchmarking environments for other simulators. Given the number of factors that impact simulation speed and rendering (e.g number of objects, geometry complexity etc.) trends that appear in results in this page may not necessarily be the case on some environments.
Currently we just compare ManiSkill to Isaac Lab on one task, Cartpole Balancing (control). For details on benchmarking methodology see this section
Raw benchmark results can be read from the .csv files in the results folder on GitHub. There are also plotted figures in that folder. Below we show a selection of some of the figures/results from testing on an RTX 4090. The figures are also sometimes annotated with the GPU memory usage in GB.
Overall, ManiSkill is faster than Isaac Lab on the majority of settings and is much more GPU memory efficient, especially for realistic camera setups. GPU memory efficiency is particularly important for machine learning methods like RL which rely on large replay buffers on the GPU. However we note that this is not a pure apples-to-apples comparison due to differences in rendering techniques and so we show a qualitative comparison of the same task in Isaac Lab and ManiSkill. See the note below for more details.
Note on rendering differences between simulators
We acknowledge that these comparisons are not strictly apples-to-apples due to differences in rendering techniques. Isaac Lab employs ray-tracing for parallel rendering, while the ManiSkill3 results are generated using SAPIEN’s rasterization renderer (see image below for a qualitative comparison), although ManiSkill3 also supports a ray-tracing mode without parallelization. Ray-tracing generally offers greater flexibility in balancing rendering speed and quality through the adjustment of parameters such as samples per pixel. It’s worth noting that the Isaac Lab data presented here uses the fastest rendering settings available in Isaac Lab v1.2.0, although it can be easily tuned to achieve better rendering quality that may be helpful for sim2real. Despite the use of different rendering techniques, we believe this experiment provides a meaningful basis for comparison.
Cartpole Balance#
Qualitative Comparisons#
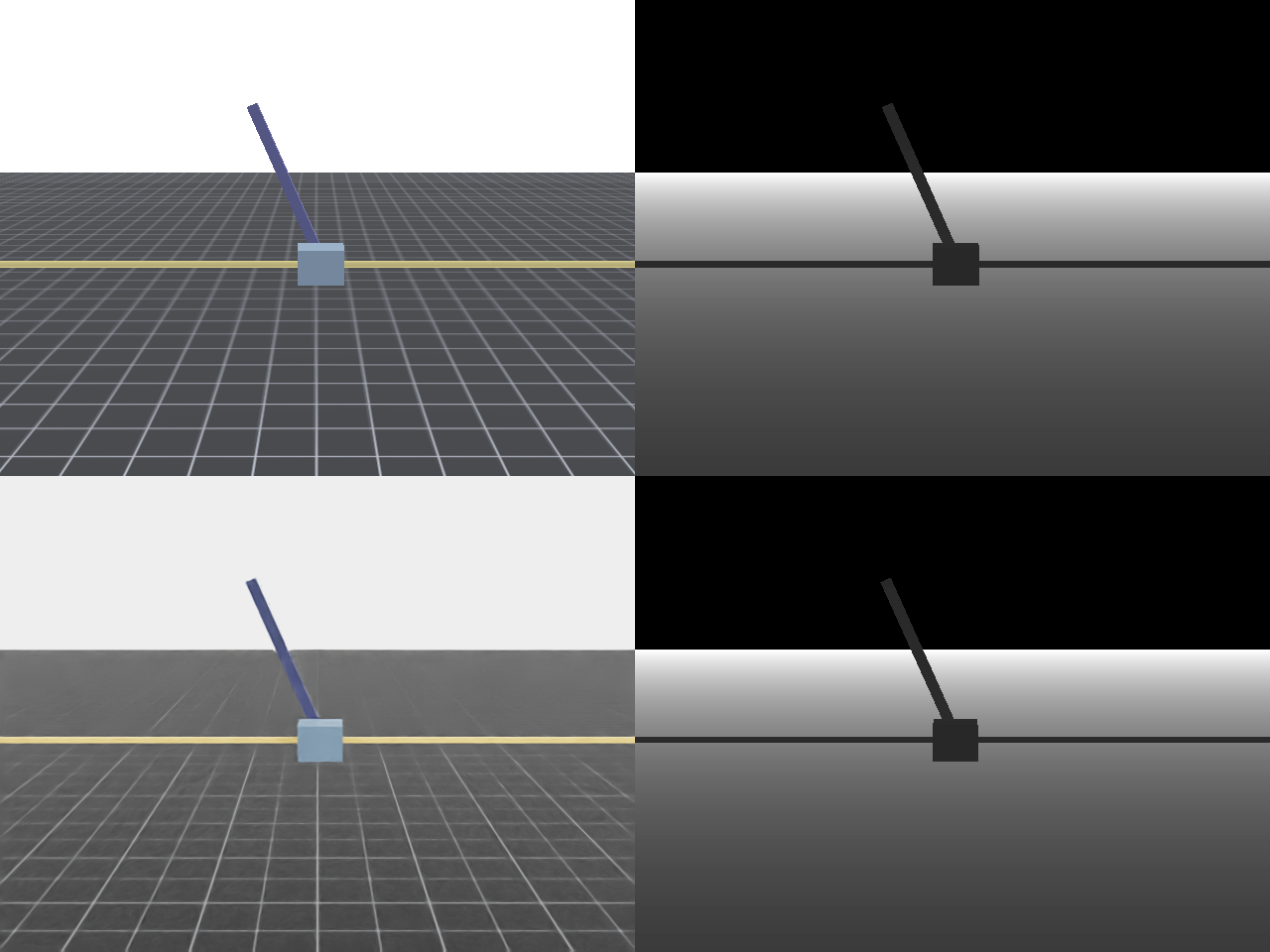
Comparison of ManiSkill (Top row) and Isaac Lab (Bottom row) parallel rendering 640x480 RGB and depth image outputs of the Cartpole benchmark task.#
Video of the task above with ManiSkill on top and Isaac Lab below.
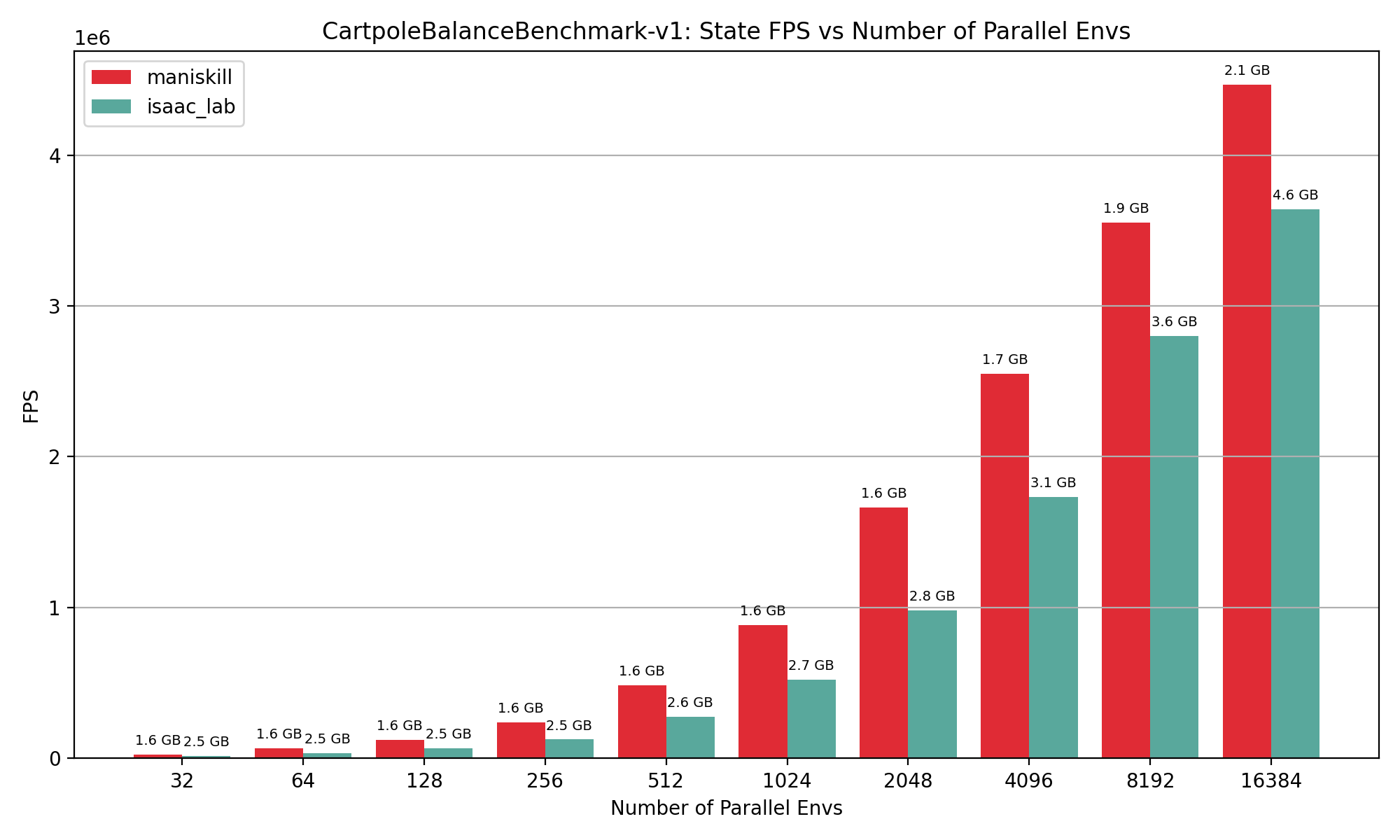
State#
CartPoleBalance simulation only performance results showing FPS vs number of environments, annotated by GPU memory usage in GB on top of data points.
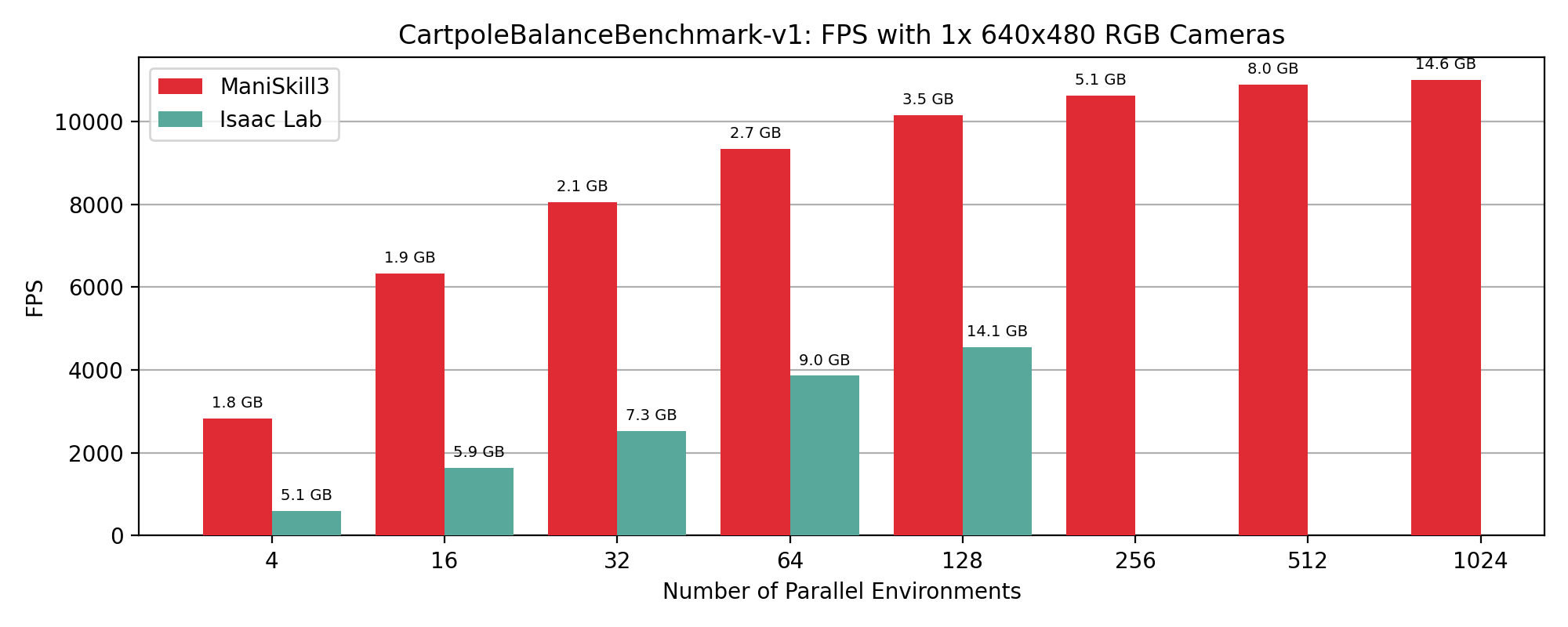
Realistic RGB Camera Setups#
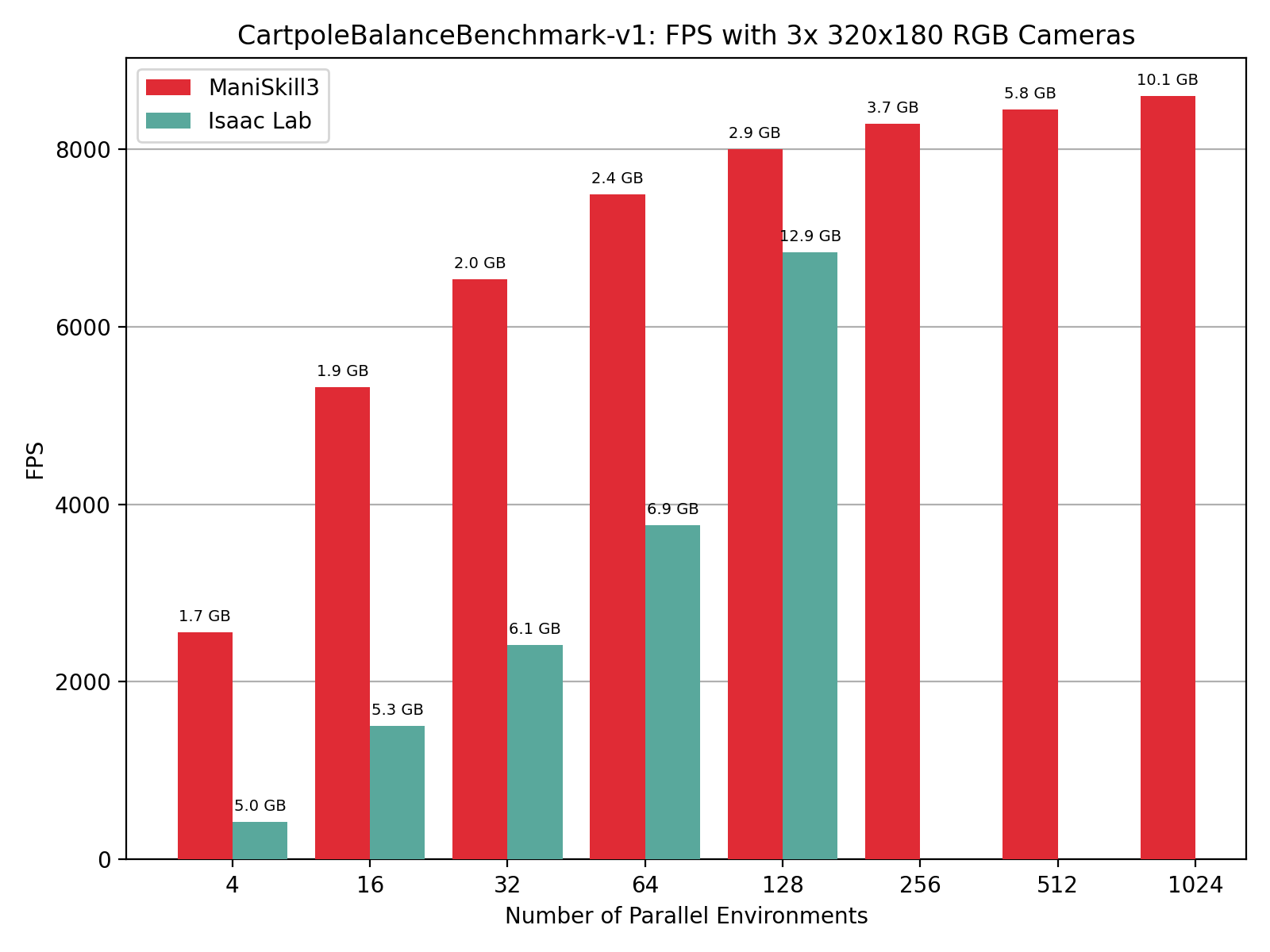
The Open-X and Droid datasets are two of the largest real-world robotics datasets. Open-X typically has a single 640x480 RGB observation while Droid has 3 320x180 RGB observations. The next 2 figures show the performance of simulators when mimicing the real world camera setups.
RGB#
CartPoleBalance simulation+rendering (rgb only) performance results showing FPS vs number of environments, annotated by GPU memory usage in GB on top of data points.
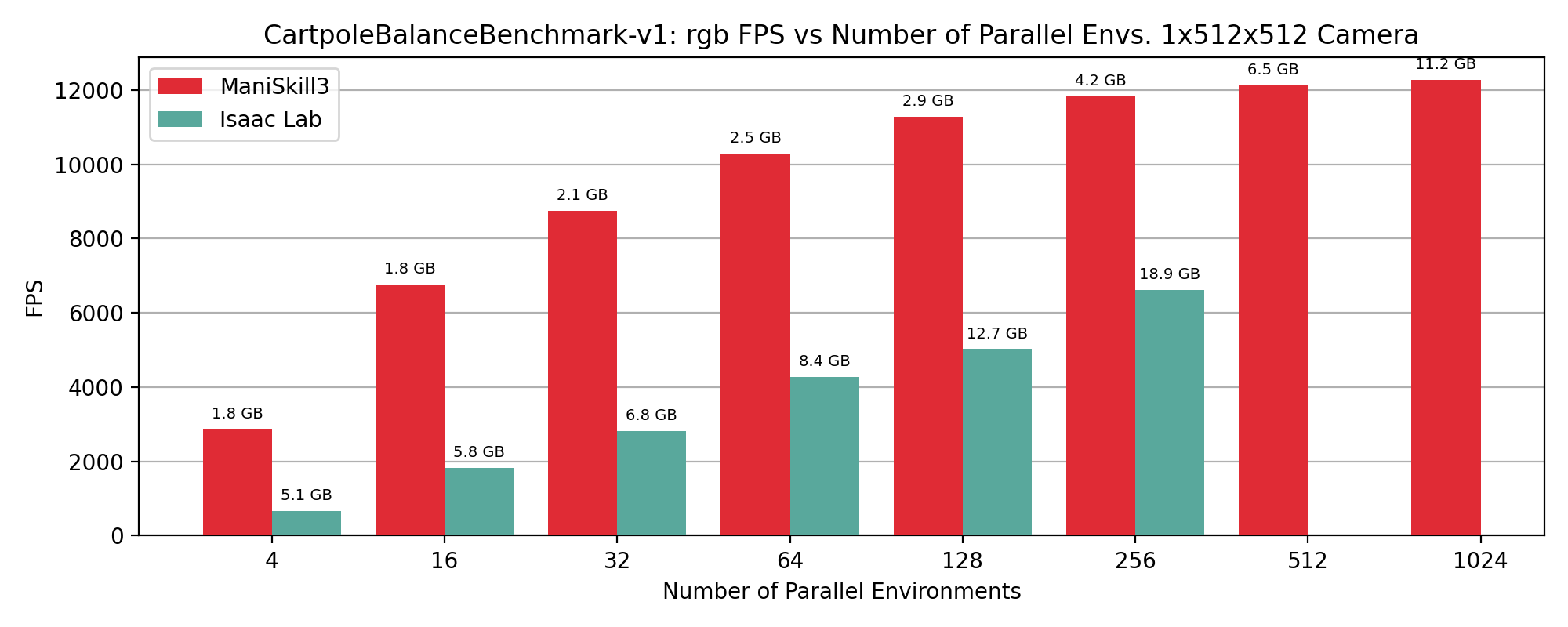
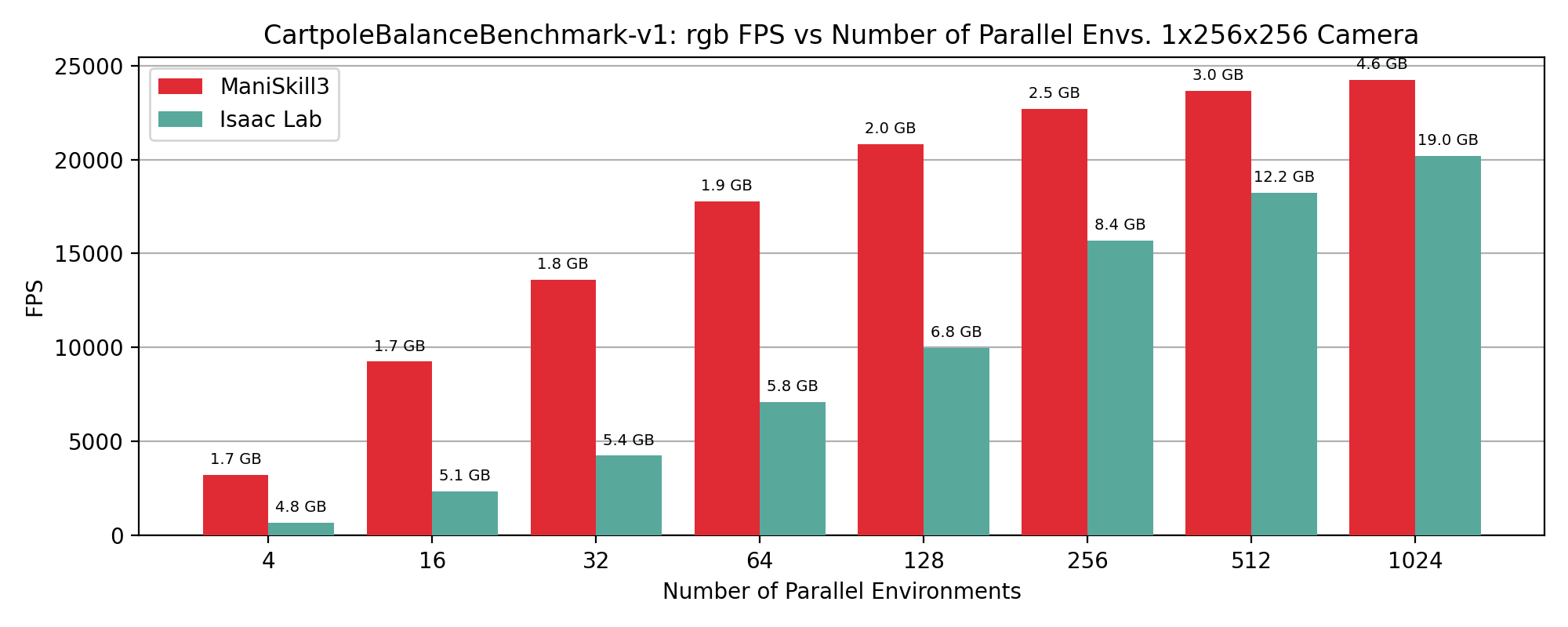
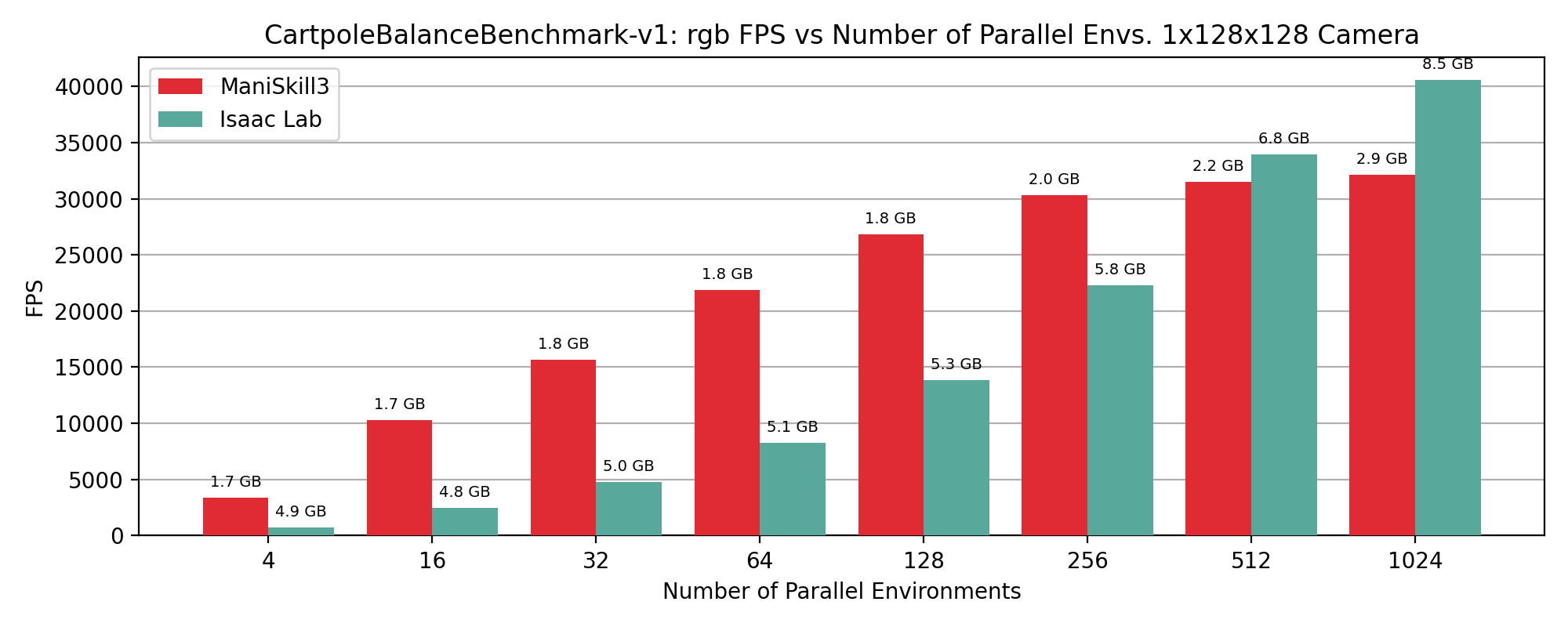
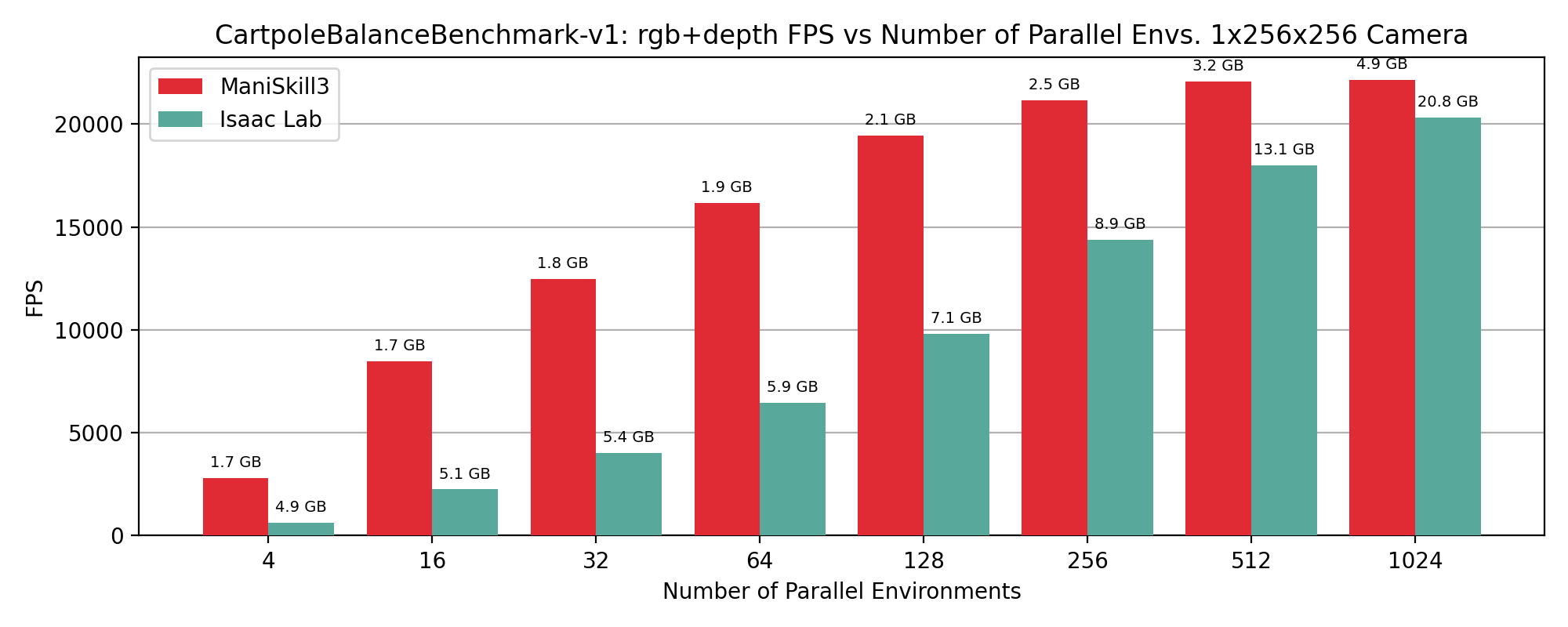
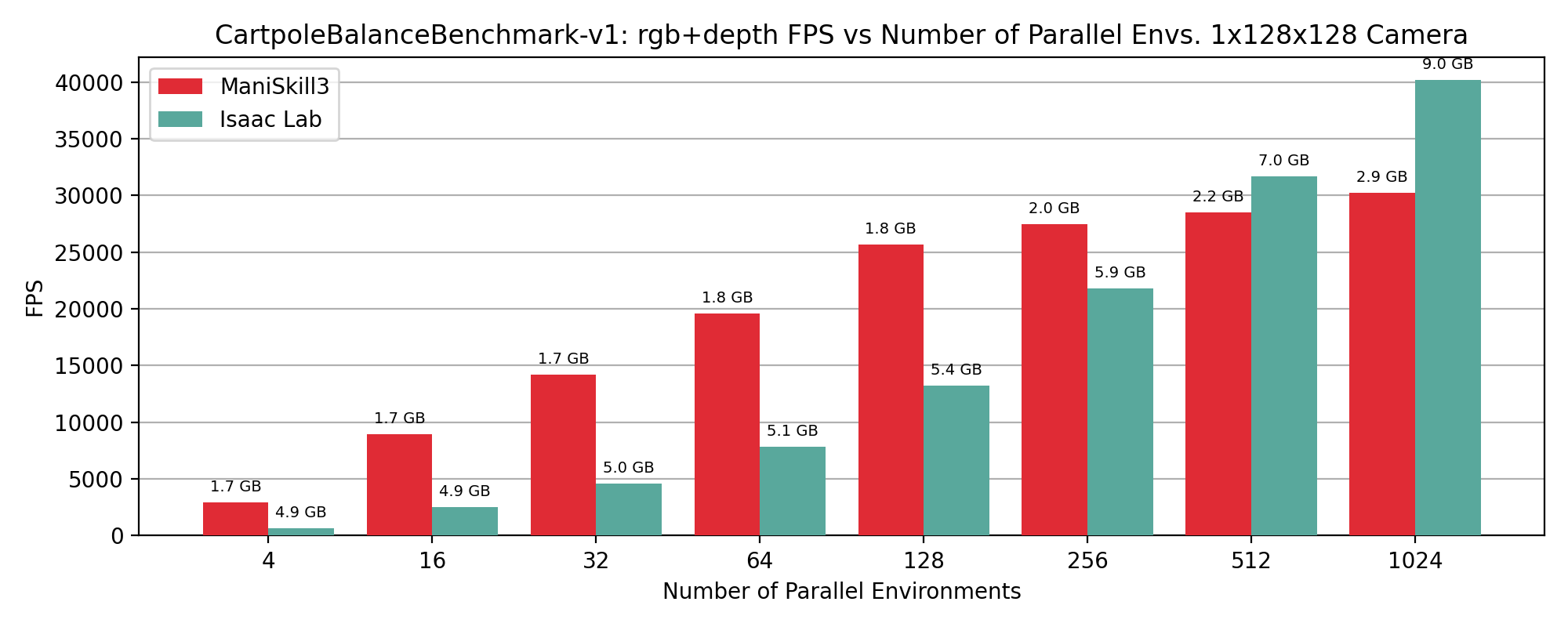
RGB+Depth#
CartPoleBalance simulation+rendering (rgb+depth) performance results showing FPS vs number of environments, annotated by GPU memory usage in GB on top of data points.
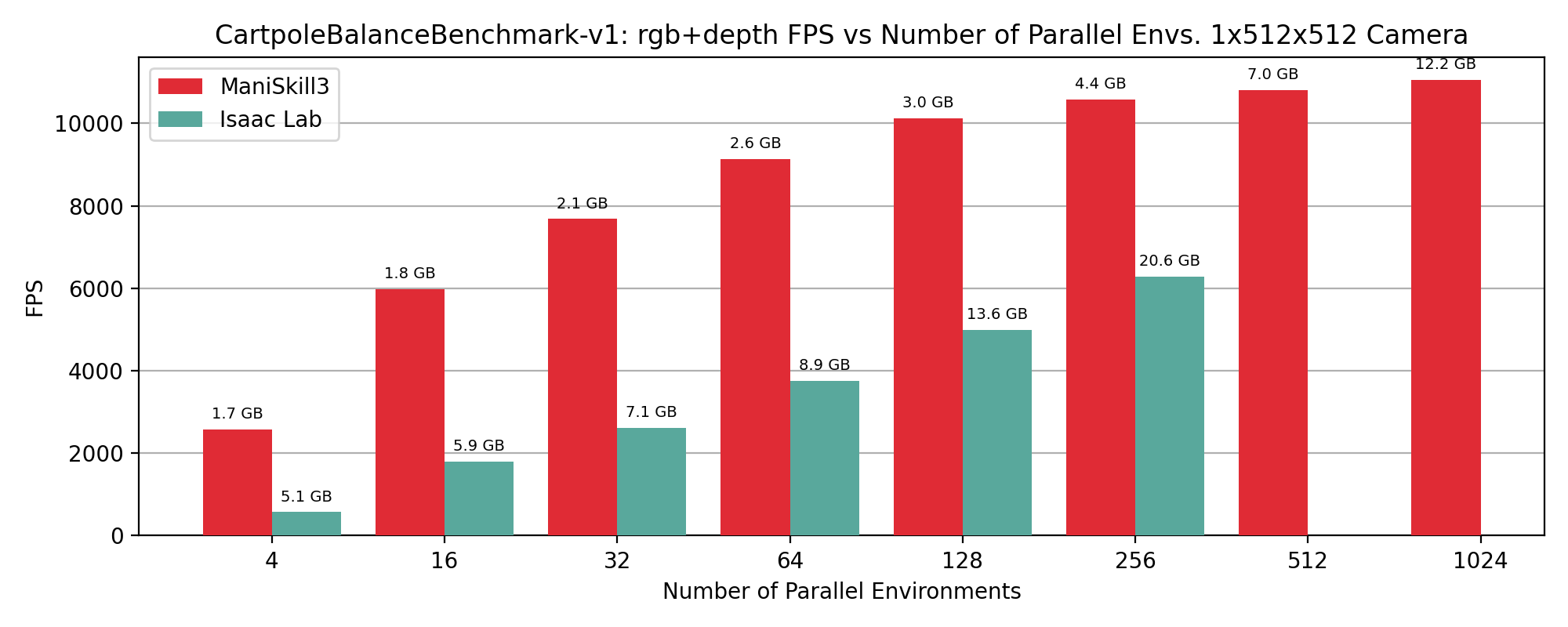
Commands for Reproducing the Results#
See the scripts under mani_skill/examples/benchmarking/scripts
Benchmarking Details/Methodology#
There is currently one benchmarked task: Cartpole Balance (classic control). Details about the exact configurations of the two tasks are detailed in the next section.
For simulators that use physx (like ManiSkill and Isaac Lab), for comparison we try to align as many simulation configuration parameters (like number of solver position iterations) as well as object types (e.g. collision meshes, size of objects etc.) as close as possible.
In the future we plan to benchmark other simulators using other physics engines (like Mujoco) although how to do so fairly is still WIP.
Reward functions and evaluation functions are purposely left out and not benchmarked.
Due to varying implementations of parallel rendering mechanisms, to benchmark the FPS when generating RGB, Depth, and/or Segmentation observations, we plot figures showing the FPS ablating on the number of parallel environments, image size, and number of cameras. Within each evaluation, we try and pick configurations that maximize the FPS when given fixed # of environments, # of cameras per environment, and/or image size.
Task Configuration#
WIP